Hey all!
I’ve been following the progress of Mycroft and similar open-source digital assistant frameworks for some time, and one area that I’ve always found to be quite challenging is a good wakeword/wake phrase framework and pre-trained models.
Mycroft Precise works fairly well, but it is relatively difficult to collect data for training new models and the false-accept rate is a bit too high in many cases. Commercial options like Picovoice Porcupine can work very well, but the limitations on custom models in the free-tier (while totally understandable) limits many applications.
As such, I’ve been working for some time on a new open-source framework and set of methods to build wakeword/wake phrase models, and the initial version was just released: openWakeWord.
You can also try a real-time demo right in your browser via HuggingFace Spaces.
By leveraging an impressive pre-trained model from Google (more details in the openWakeWord repo) and some of the text-to-speech advances from the last two years, I’ve been able to train models with 100% synthetic audio and still show good performance on real-world examples. For example, here is the false-accept/false-reject curve for Picovoice Porcupine, openWakeWord, and Precise for a “hey mycroft” model based on real-world examples that I collected. None of the these models were trained on my voice at any point.
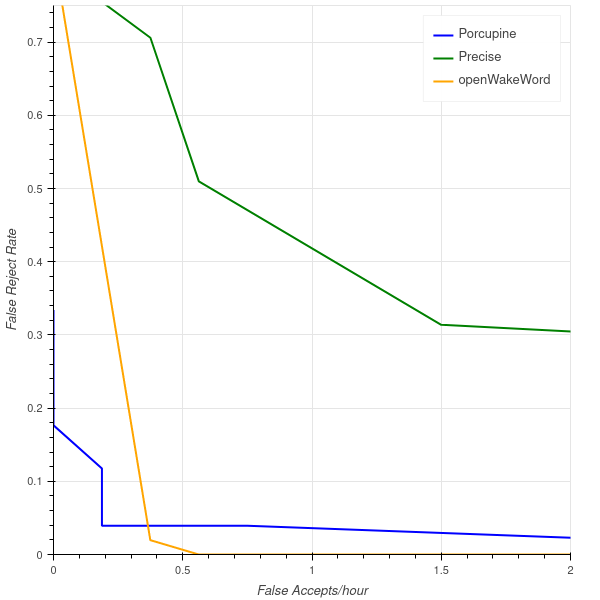
If anyone finds this interesting or useful I would greatly appreciate feedback on how well the models work for different voices and environments, as well as general suggestions for new features and improvements.
Thanks!