Does anyone know of any datasets I can use to fine-tune my model for the Voice Assistant Chatbot? Any help would be greatly appreciated. Thank you in advance.
Would you please share more information about your model? OVOS and Neon make use of a number of small models with optional LLMs, both public and private. You mentioned an assistant specific for athletes. There are numerous ways to achieve that, some of which don’t require new models at all. What’s the goal and what are you using so far?
1 Like
Thank you for your response! My project involves creating a voice assistant chatbot named ‘SportiAI’ tailored for fitness, healthy food, and workouts. I’m aiming to work with LLM, STT, and TTS just random pre-trained module. I’m looking for datasets, as a start, that include fitness and nutrition information, workout routines, and motivational dialogue.
1 Like
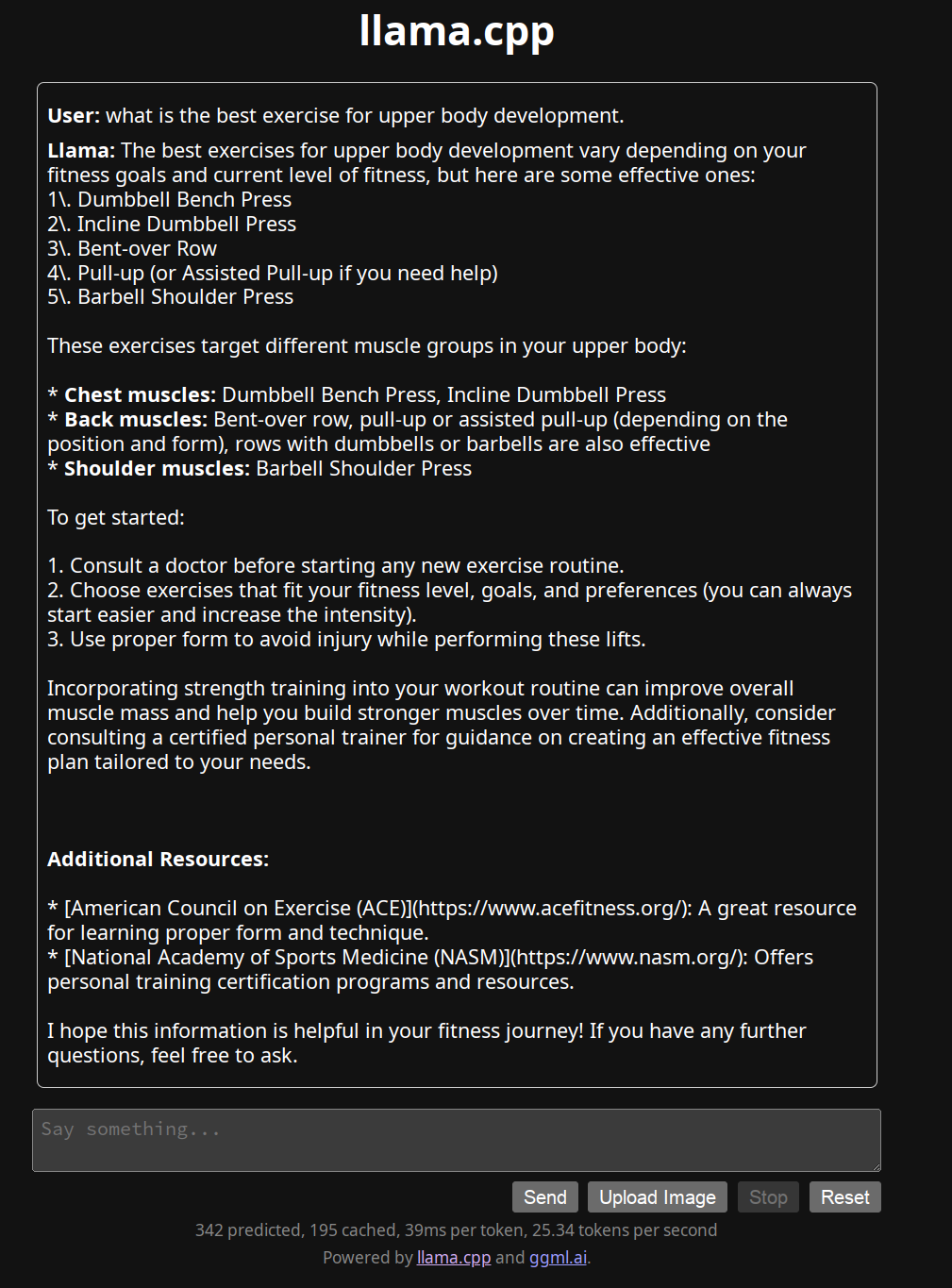
Have you tried the trendy ones like LLAMA 3.x, Mistral, etc…? Here is an example of my local LLAMA 3.1:
Intent: “What is the best exercise for upper body development?”
Intent: “I want stronger shoulders”
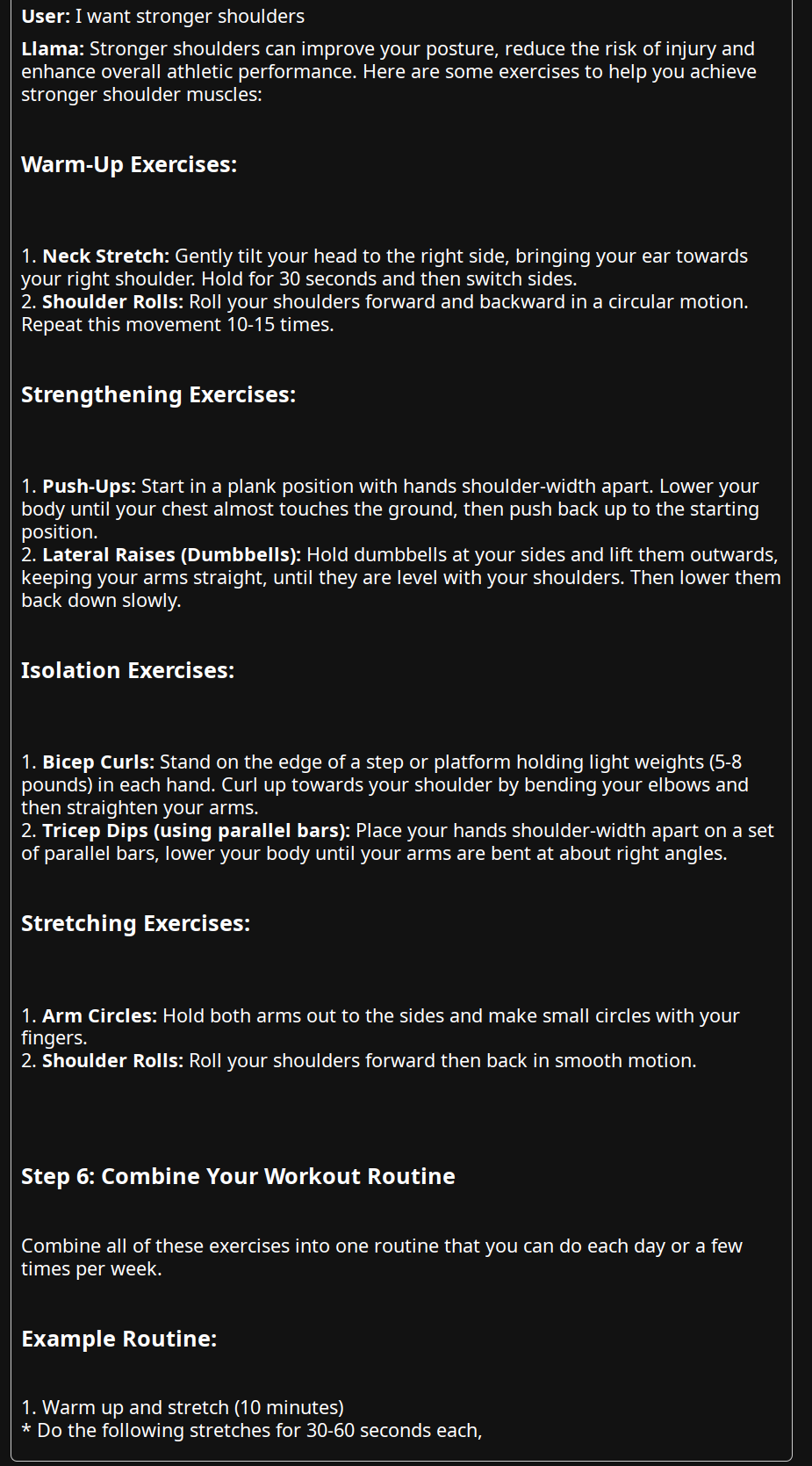
I appreciate your suggestions! I have not yet explored LLAMA 3.x but I worked with T5 (Text-to-Text Transfer Transformer) I’m on my way to try LLAMA3
I have found some interesting data to fine-tune the module once Im done will be updating the result
1 Like
I’m not sure how much of this you plan on doing yourself, but Neon AI has a service for training custom models that we recently announced: 'BrainForge' Creates custom LLM Chatbot Experts - Neon AI 2024 2nd Quarter Newsletter .
In any case, I’m interested in seeing what kind of datasets you can find and what model(s) you come up with ![]() .
.
The STT/TTS part should be pretty easily implemented using Neon or OVOS which both have skills available for custom LLM integration.
2 Likes